Отчёт о составлении семантического ядра сайта
Здравствуйте. На связи Габдуллин Ильяс, автор сайта qixy.ru.
В этой статье я хотел бы кратко пробежаться по основным самым интересным моментам, с которыми я столкнулся при создании своего сайта, посвященному волонтерству ilvee.ru. Я расскажу вам в основном про технические решения, которые мне удалось реализовать при работе над сайтом — выбором темы оформления, необходимых плагинов, настройкой безопасности.
Особое внимание я собираюсь уделить SEO — внутренней поисковой оптимизации и составлению семантического ядра.
Для тех кто не знаком с этими понятиями — это необходимо для того чтобы сайт ранжировался высоко в выдаче поисковых систем и у него была посещаемость. Проще говоря, сайт должен быть интересен людям, удобным и с актуальным контентом, иначе людям не было бы пользы от сайта, и значит и смысла его создавать ?. Итак, приступим.
Дизайн и базовые настройки
Сайт я сделал на одной их самых популярных систем управления сайтов WordPress. Сайт, построенный на Вордпресс можно очень гибко настраивать как в плане дизайна, так и функционала. Это благодаря наличию огромного выбора различных расширений — тем и плагинов. Конечно очень сложно выбирать дизайн будущего сайта, особенно когда вокруг тысячи потрясающих примеров оформлений современных сайтов. Но тем не менее я сделал свой скромный субъективный выбор.
Самые необходимые технические настройки:
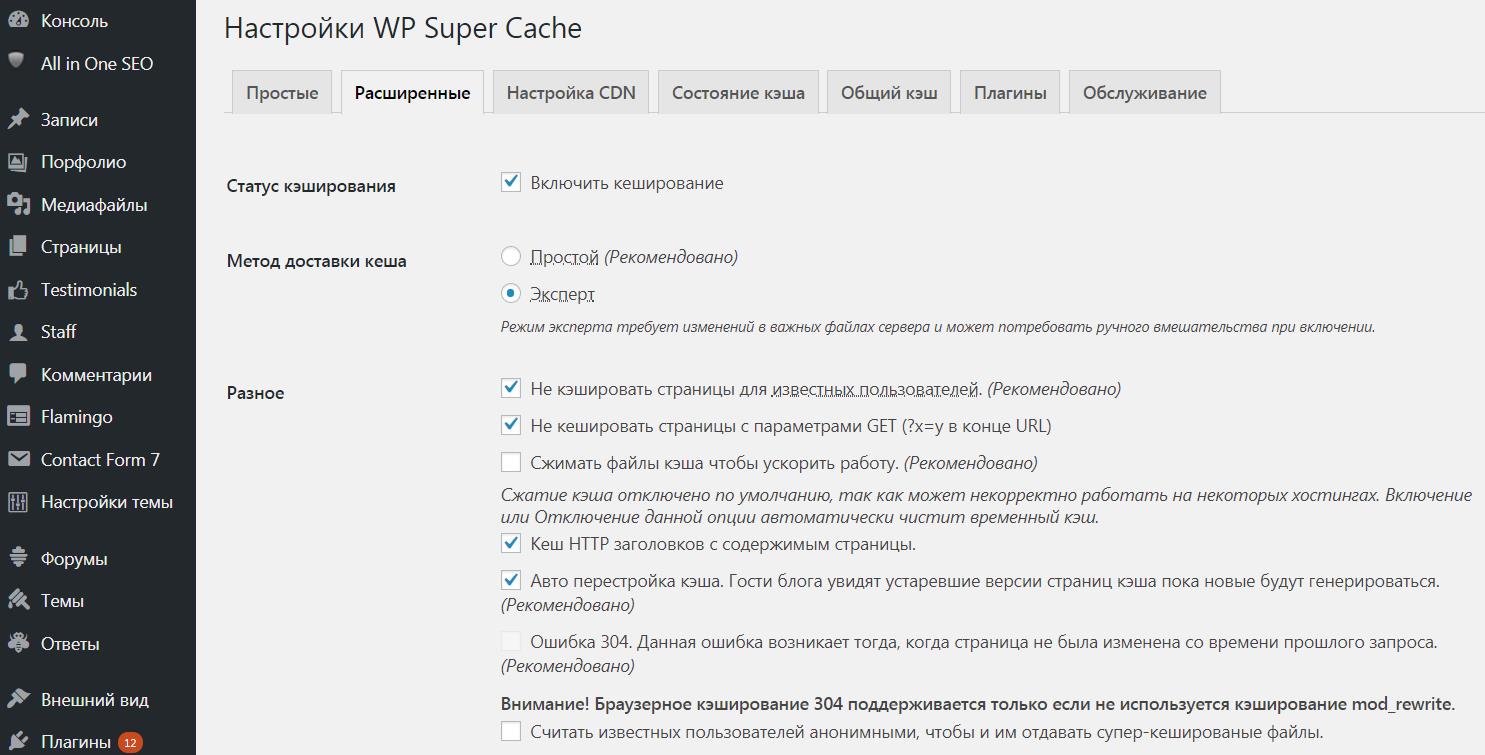
- Настроено кеширование (браузерное и файловое) что позволит выдержать суточную нагрузку в десятки тысяч посетителей. (плагин WP-SuperCache)
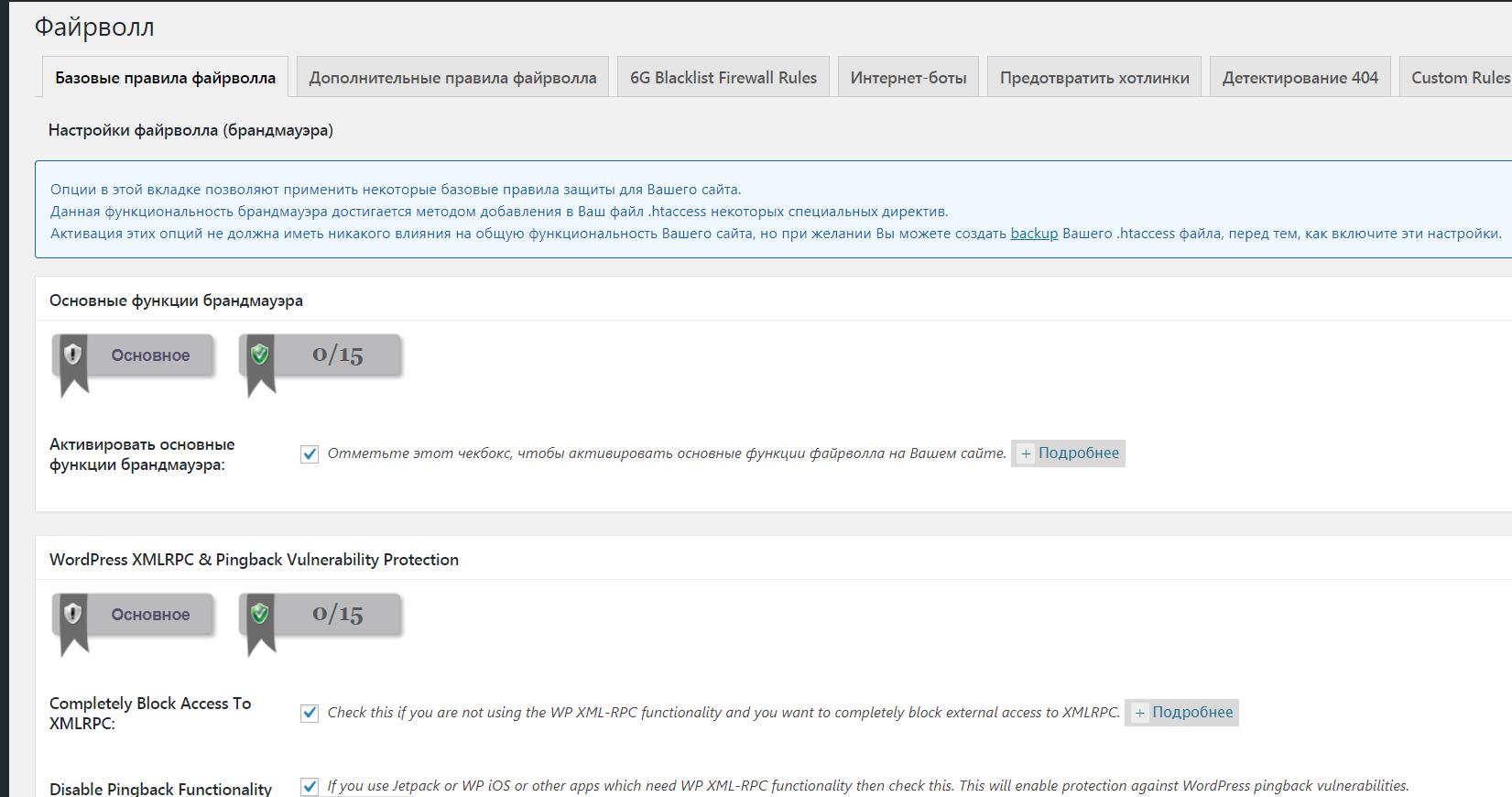
- Настроены плагины комплексной защиты от взлома и вирусных атак. (плагин WP-AllinOneSecurity)
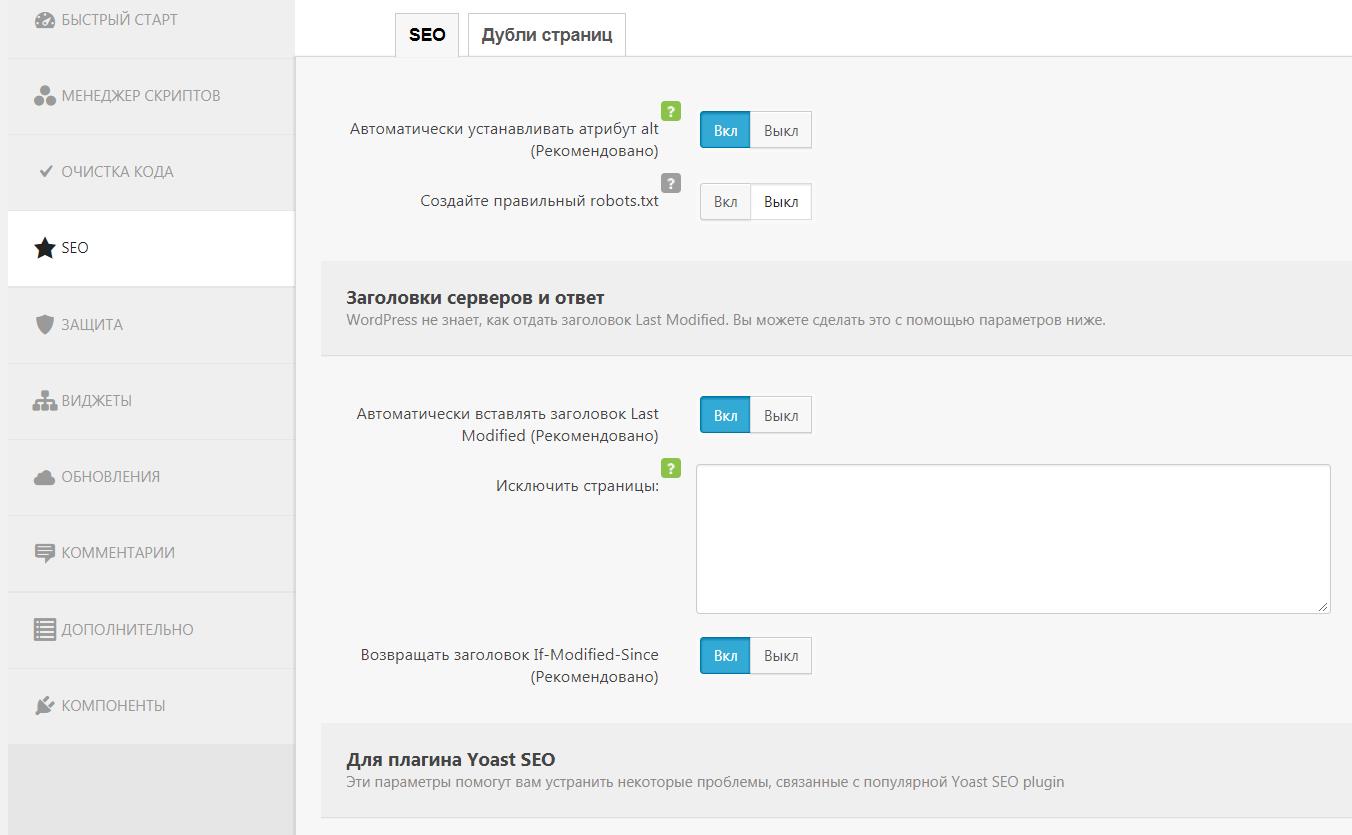
- Настроено комплексное SEO (оптимизация под поисковые системы) — теги и метатеги ко всем страницам (title, description, h1-h5), файл с директивами для поисковых систем robots.txt, карты сайта для поисковых систем sitemap.xml и карта сайта для людей др.. (плагины WP-AllinOneSeoPack, DDSitemapgen)
- Установлено автоматическое регулярное создание резервных копий по расписанию (основных файлов и базы данных сайта) на всякий случай. (плагин UpdraftPlus)
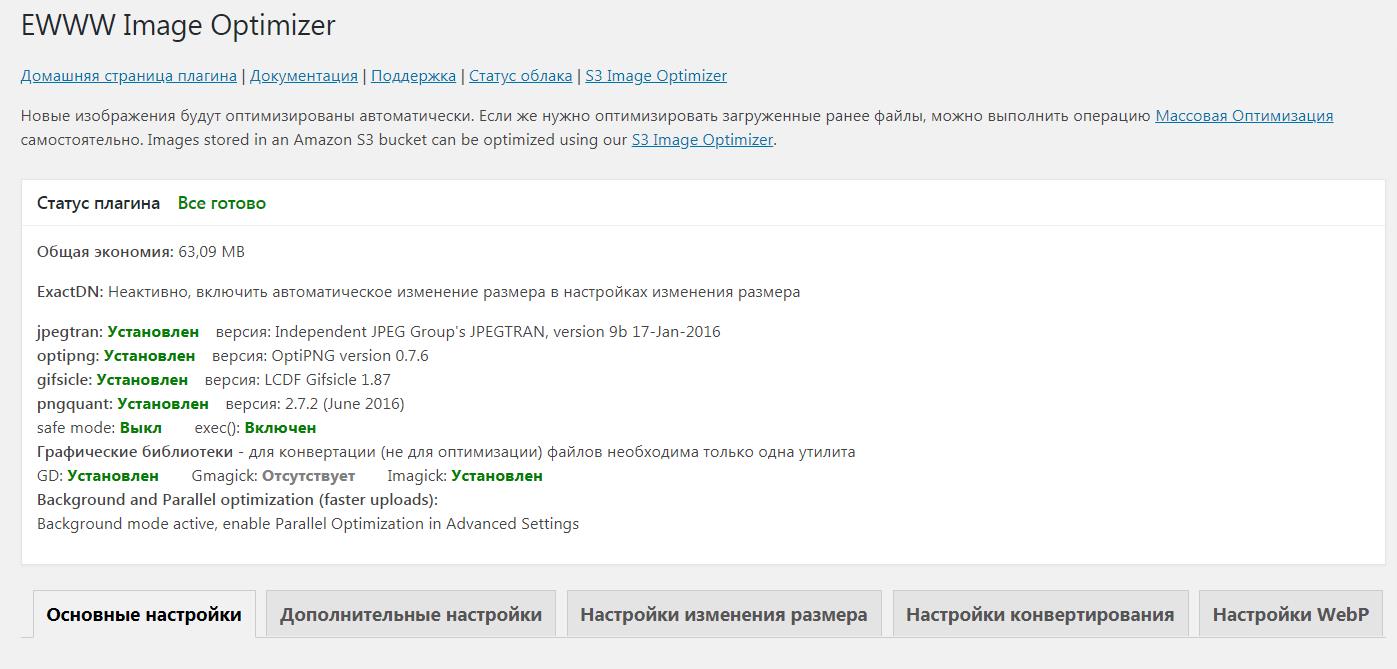
- Остальные настройки — оптимизация изображений, ускорение скорости загрузки сайта и др.. (плагины Clearfy, EWWW)
Подробно углубляться в этой статье во все многочисленные настройки движка я не буду, однако на скриншотах ниже я выборочно показал некоторые настройки в админке и в плагинах WordPress:
SEO (оптимизация под поисковые системы)
Это, пожалуй, самое интересное. Именно то, ради чего я стал писать эту статью ?.
 Пару слов для новичков в SEO — даже хорошо сделанный и оптимизированный сайт будет абсолютно бесполезен без посетителей. Сайту необходимо правильное поисковое продвижение для того чтобы информация нашла свою целевую аудиторию. Чтобы сайт имел высокие позиции в поисковой выдаче необходимо комплексное и эффективное поисковое продвижение. Ведь если сайт не будет нравиться посетителям, то тогда они быстро будут покидать его.
Пару слов для новичков в SEO — даже хорошо сделанный и оптимизированный сайт будет абсолютно бесполезен без посетителей. Сайту необходимо правильное поисковое продвижение для того чтобы информация нашла свою целевую аудиторию. Чтобы сайт имел высокие позиции в поисковой выдаче необходимо комплексное и эффективное поисковое продвижение. Ведь если сайт не будет нравиться посетителям, то тогда они быстро будут покидать его.
Поисковые системы точно фиксируют такого рода поведенческие факторы и умеют определять какой сайт интереснее людям а какой нет, и соответственно, какой из них ставить выше в выдаче на поисковые запросы. Поэтому самое главное — это качественный и интересный контент, релевантный к запросам по которым посетители приходят на сайт из ПС. Как узнать какой контент размещать на сайте? что интересует людей больше всего в определенной тематике?
Ответы дают сами поисковые системы, например, сервис Wordstat от Яндекса (wordstat.yandex.ru). Таким образом, ориентируясь на потребности самих пользователей, мы можем составить семантическое ядро сайта определить наиболее востребованные и релевантные поисковые запросы под которые в дальнейшем регулярно создавать качественный контент. Я пользуюсь специальными СЕО-программами (KeyCollector) и сервисами для того чтобы создать качественное семантическое ядро (СЯ).
Составление семантического ядра сайта
Краткий план действий:
- Подбор базовых запросов.
- Подбор минус-слов.
- Парсинг ключей в Вордстат.
- Сбор поисковых подсказок в Яндексе и Гугле.
- Составление общего списка запросов и подсказок.
- Сбор частотности.
- Чистка списка от мусора.
- Деление запросов на коммерческие и информационные.
- Вычисление полноты, убираем пустые запросы.
- Финальная кластеризация.
- Ручная доработка по кластеризации.
- Работа над структурой сайта.
- Планирование страниц.
- Прописываем ЧПУ, метатеги Title, H1, description
- Составление точного ТЗ для написания текстов.
Если вас не отпугнула изложенная выше информация и вы готовы почитать мой подробный разбор действий по составлению СЯ, то вы большой молодец ?.
Итак, какие исходные данные я имею сейчас? У меня есть заранее подготовленная тематика для сайта, а именно это «Волонтёрское движение: прошлое, настоящее, будущее«. Тематика довольно обширная. Очевидно, что если этот сайт у нас будет информационный, то на таком сайте может быть множество разных разделов и структура сайта может быть большой.
Нам известно несколько основных разделов в структуре нашего сайта, которые я определил сам. Их можно обобщить такими ключевиками:
— волонтёрство
— помощь
— как помочь
— добро
— доброволец
На этом моя фантазия закончилась, этого очень мало для полного раскрытия нашей тематики. Мы ведь хотим собрать максимально полное СЯ, правда? Значит нужно более подробнее углубляться в нашу тематику, изучать её вдоль и поперек. Кроме того, наши начальные фразы слишком общие и годятся лишь для того чтобы отталкиваться от них дальше.
Для начала пойдём черпнём вдохновение в поисковой выдаче, просматривая сайты конкурентов. Анализируя данную нишу, я пришел к выводу что тематику связанную с волонтёрством вполне могут дополнять такие фразы как:
— волонтёрство
— помощь
— как помочь
— добро
— доброволец
— добровольческий
— добродетель
— благотворительность
— милосердие
— бескорыстно
— фонд
— фонд помощи
— письма добра
— вдохновение
— истории жизни
— помочь детям
— ветераны
— пожилые
— помощь животным
— благоустройство
— здоровый образ жизни
— нет мусору
То есть у нас есть несколько фраз, в общих чертах определяющих тематику нашего сайта. Наши фразы 1-2-словные, в них всё ещё нет достаточной конкретики даже для того чтобы построить развернутую логическую структуру сайта. Попробуем заглянуть по этим фразам в базы поисковых запросов, которые содержат в себе всю статистику по частотностям. Идём в сервис Букварикс (bukvarix.com). Уже сразу видно что по слову «добро» нашлось много интересных результатов, но в то же время есть и совсем не подходящие для нас, мусорные фразы.
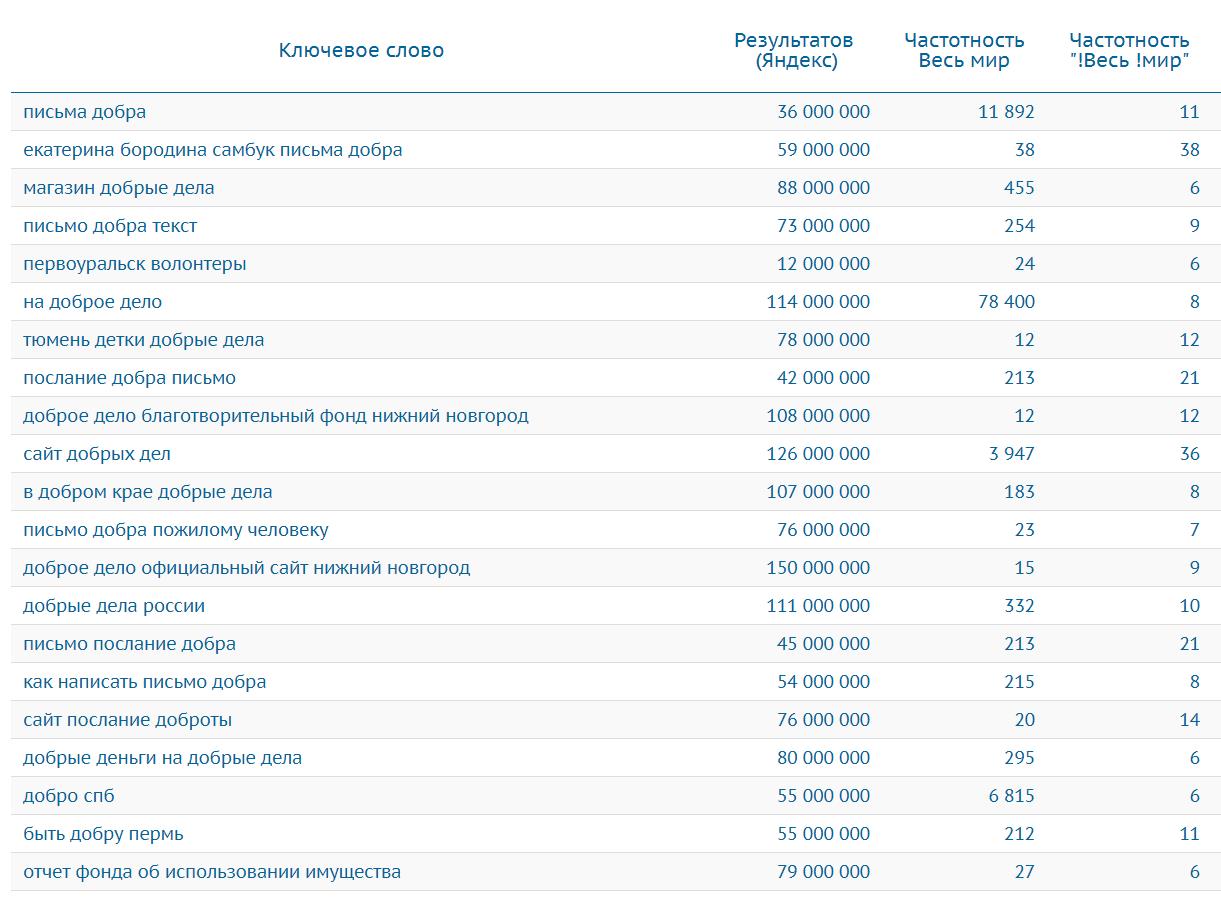
Соберем списки фраз для остальных входных слов и выгрузим весь список в таблицу Excel для более удобной работы с запросами. У меня получился нехилый список из около 7000 фраз ?. Отсортируем по убыванию точной частотности и посмотрим что ищут люди.
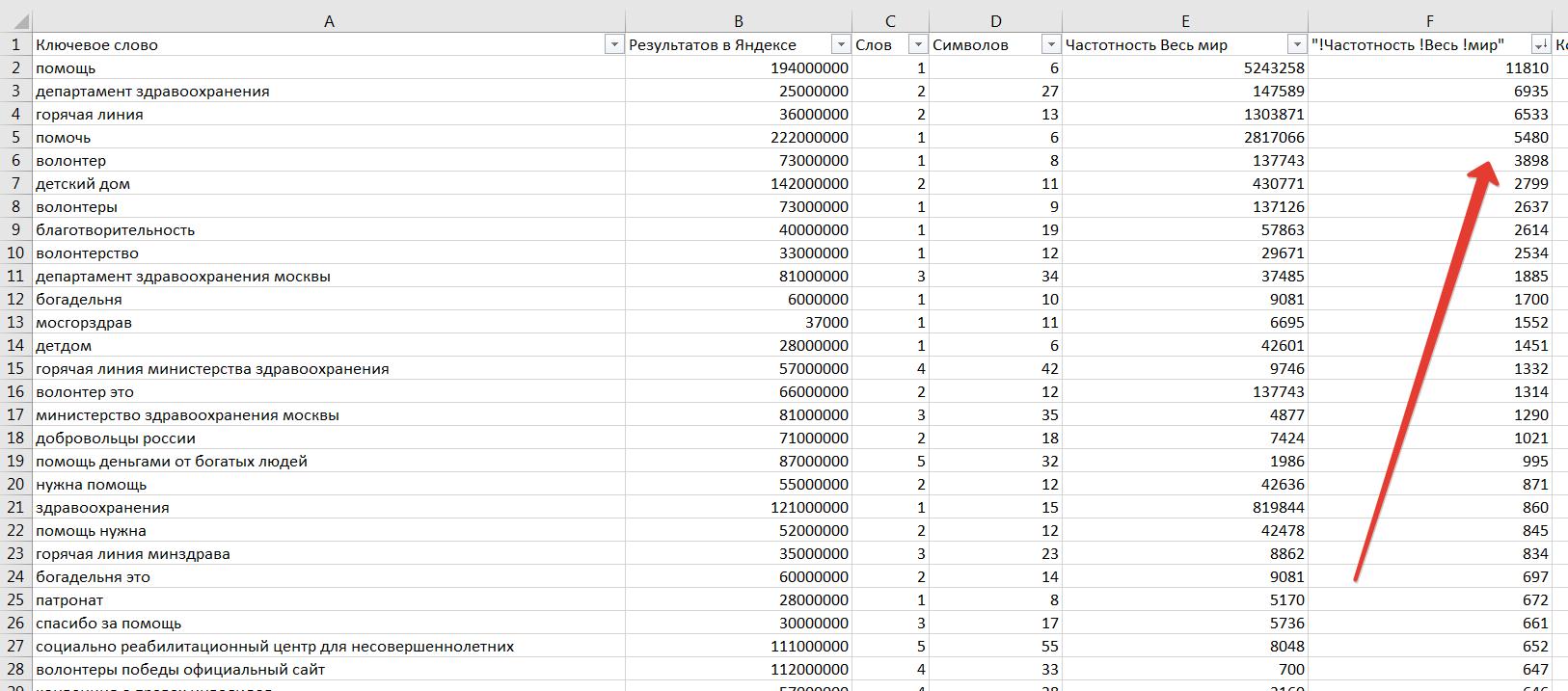
Я отобрал наиболее частотные (от 50 запросов в месяц). После предварительной чистки осталось около 200 фраз. Теперь попробуем на основе этих фраз найти более сложные по составу фразы и другие словоформы (то есть распарсить хвосты по этим ключевикам).
Начинаем работать с программой KeyCollector. Для начала воспользуемся специальным инструментом и проведем анализ неявных дублей, то есть удалим аналогичные словоформы, так как поисковые системы считают такие фразы идентичными. Нашлось несколько десятков дублей.
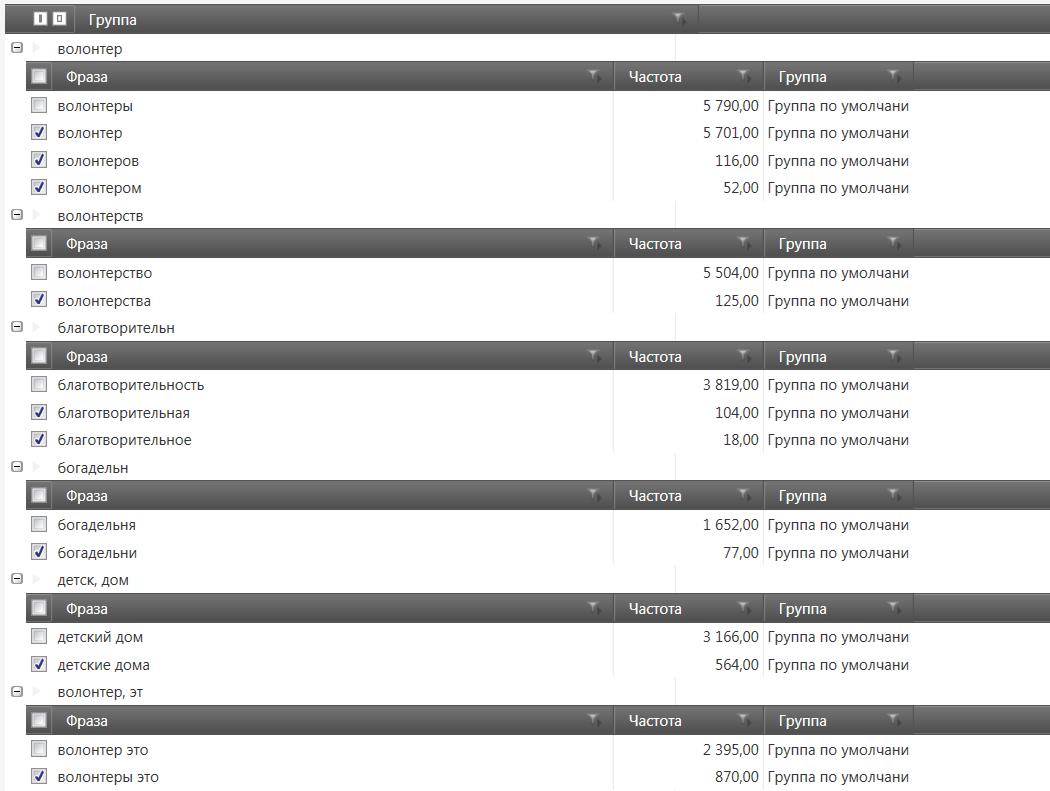
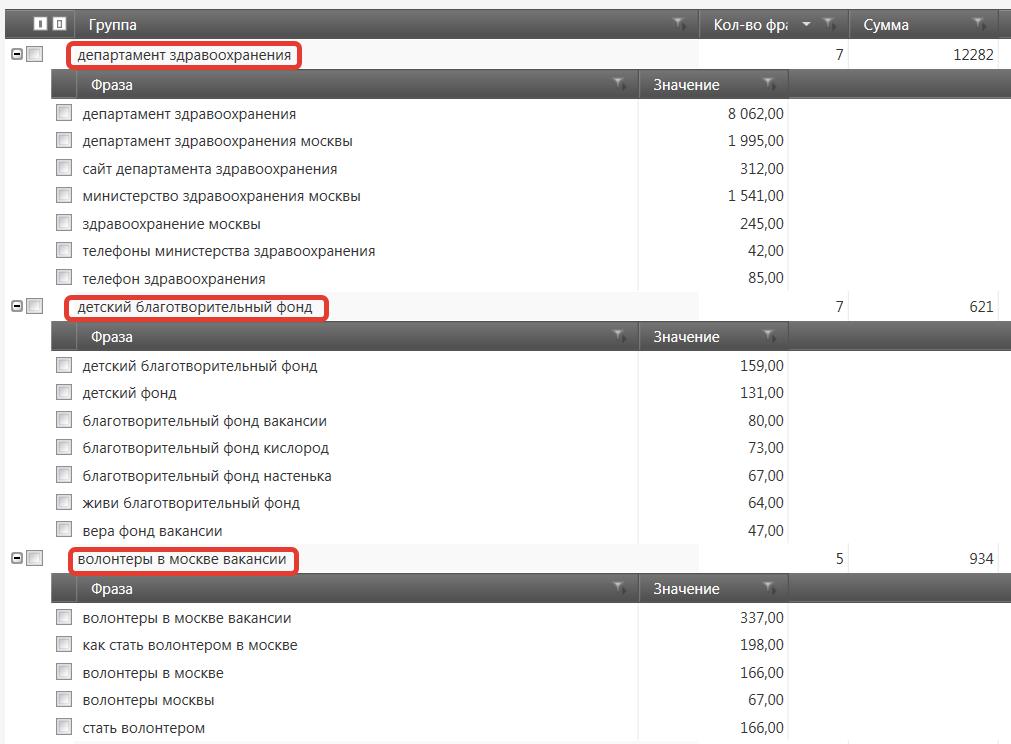
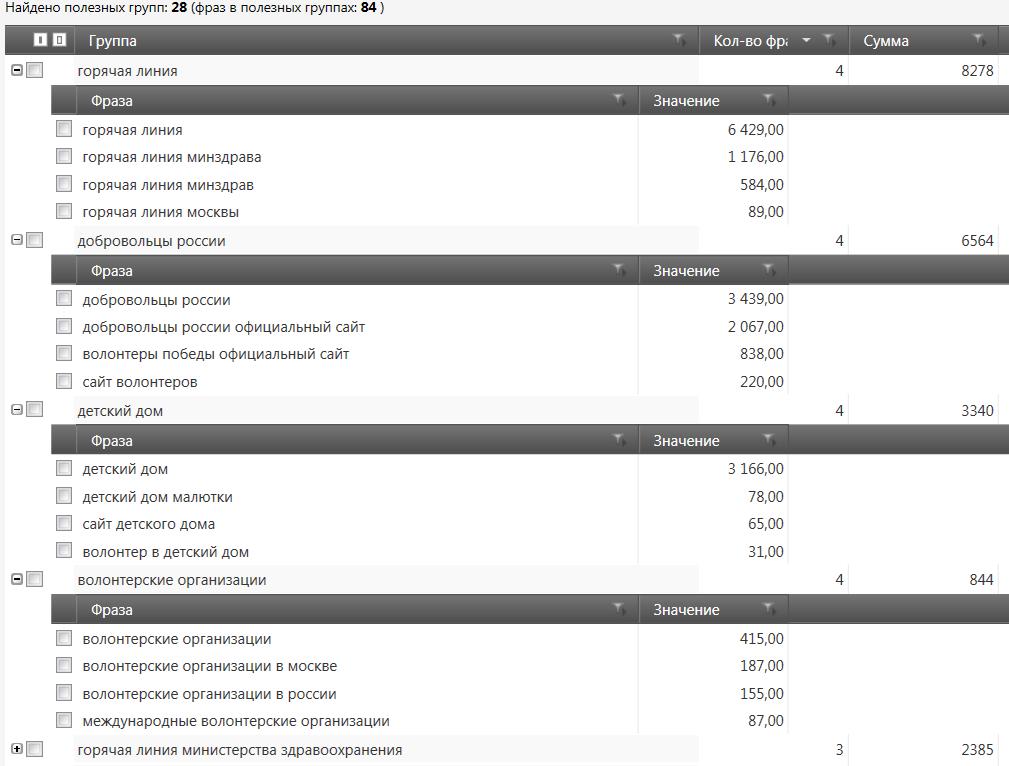
Теперь нужно проанализировать группы, для начала глянем частотный словарь по нашему списку фраз. Здесь мы видим какие слова используются чаще всего. На этом этапе у меня в голове уже вырисовывается логическая структура сайта.
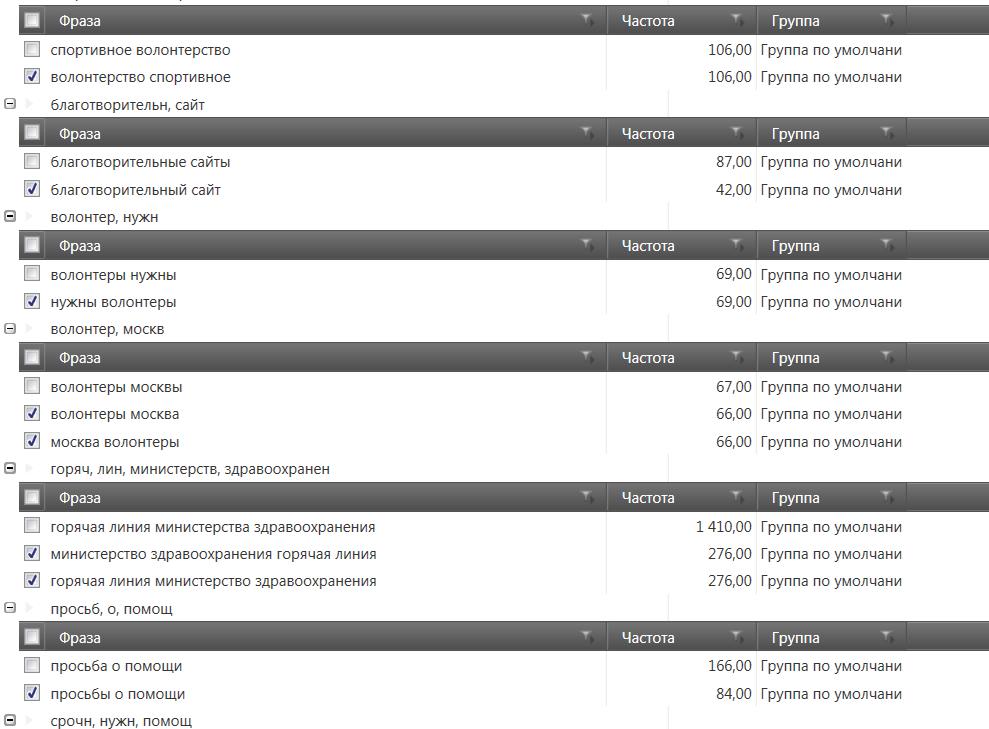
Но лучше всего посмотреть каким образом сгруппируются фразы по составу фраз (совпадения по 2 и более словоформам). Как мы видим получилось много небольших групп, однако они обладают высокой семантической схожестью.
Все выше проделанные мною действия являлись лишь этапом составления основных групп запросов и общей семантической структуры сайта.



Теперь, используя нашу структуру с группами и входными фразами в них, приступаем к сбору всех возможных запросов из сервиса статистики Вордстат (wordstat.yandex.ru). Если не знаете о принципе работы этого сервиса — просто введите в поле поиска любой поисковый запрос и вы получите от него множество фраз-«хвостов» и частотности к ним.
Собрав 20000 запросов я приступил к чистке этого списка, от фраз не подходящих моему сайту. Для этого я использую всё тот же частотный словарь и определяя неподходящие нам запросы, добавляя их в список стоп-слов. На скринах ниже пример таких слов, абсолютно не подходящих для нашей тематики, и соответственно группы фраз содержащих данные стоп-слова.
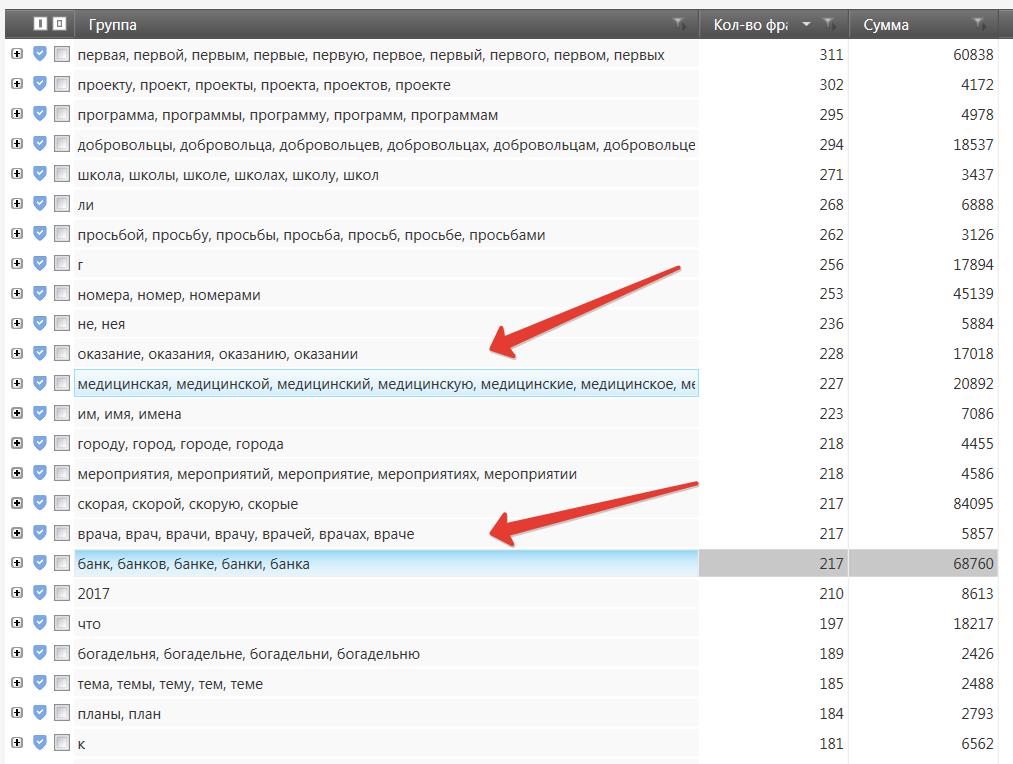
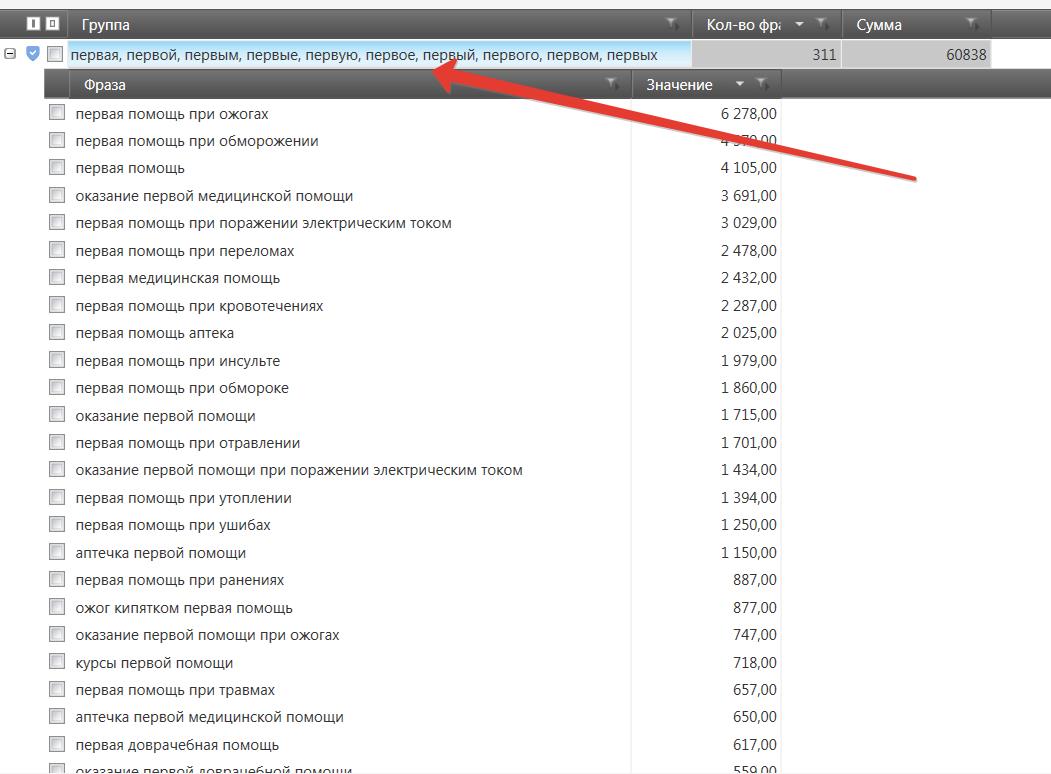
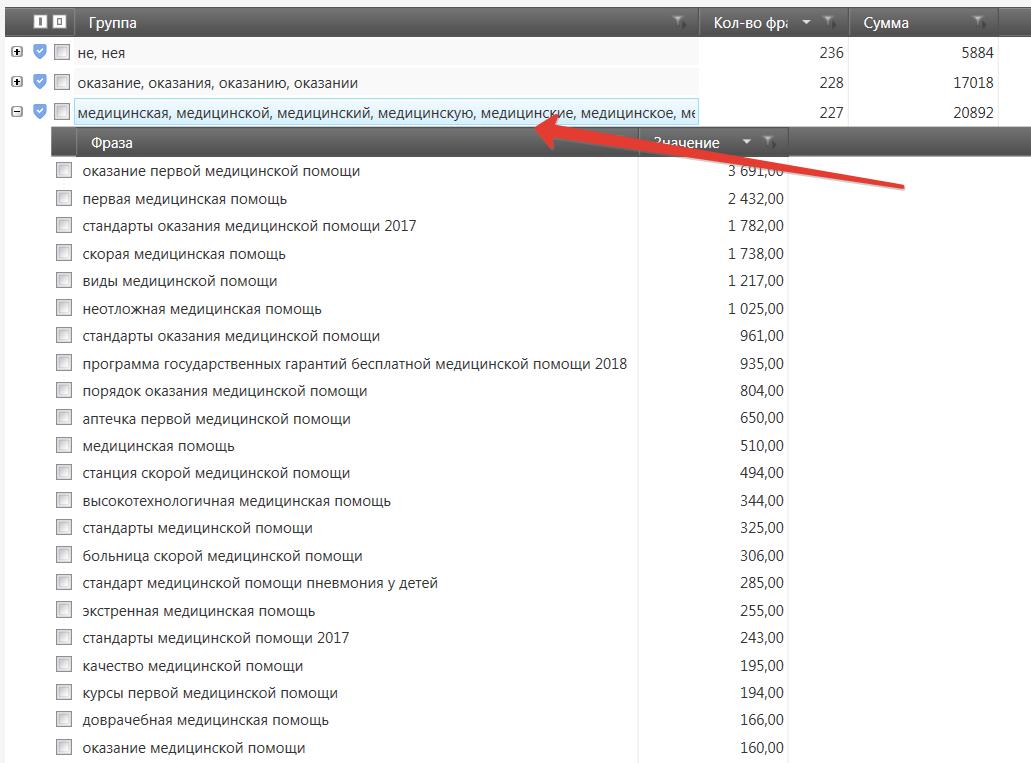
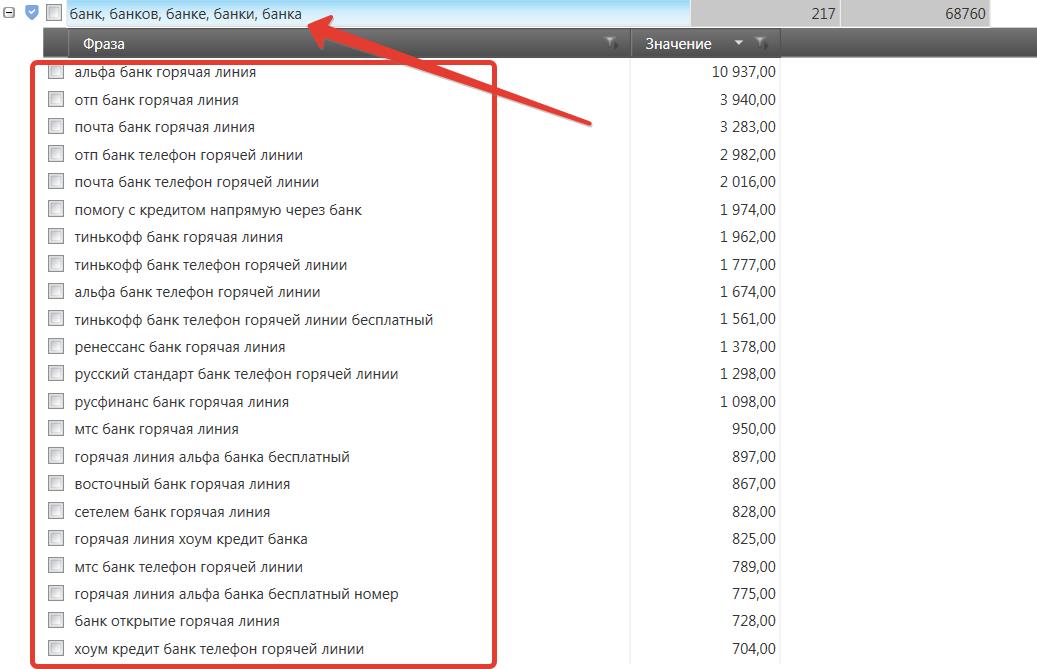
Я отсеял более 18000 мусорных запросов. Вот какой список стоп-слов у меня получилось собрать в процессе чистки:
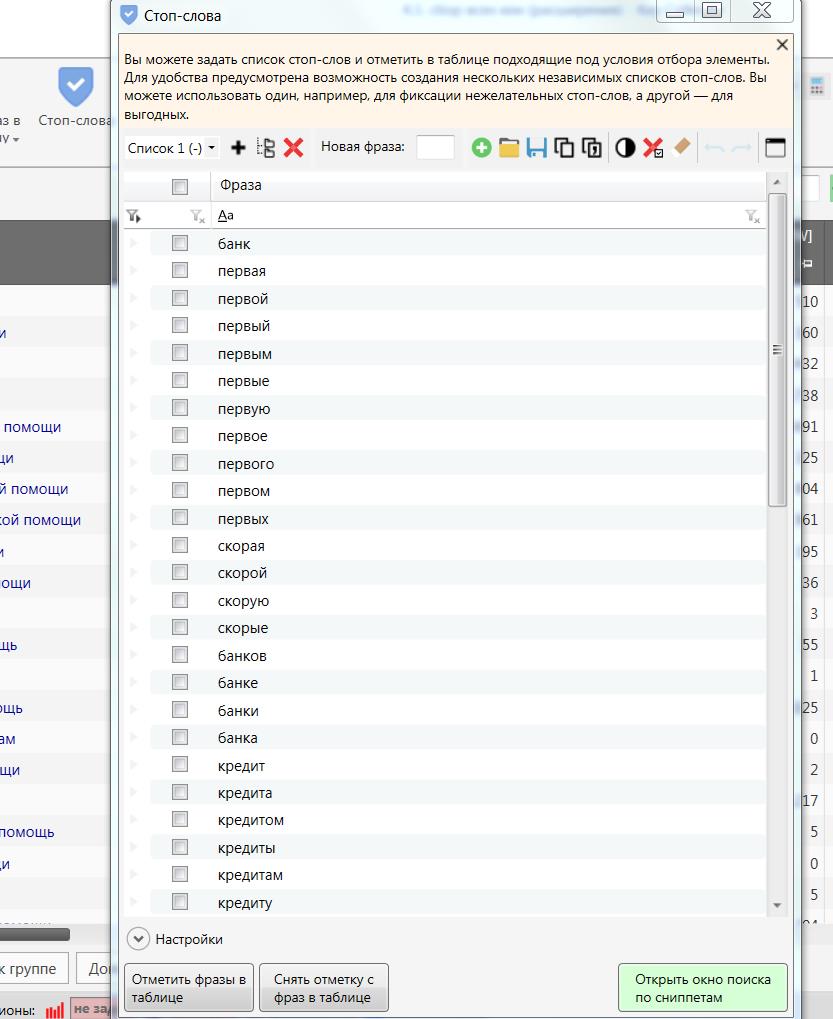
Можете посмотреть список в текстовом файле Стоп-слова.txt или Скачать файл. Конечно, сейчас данный список стоп-слов ещё совсем небольшой, но тем не менее он крайне важен для эффективной работы с СЯ, и по мере расширения и чистки СЯ он будет пополняться. Главное то что вы на этом примере поняли саму суть данного процесса.
Теперь займемся кластеризацией — объединим наиболее подходящие друг другу фразы в мини группы. Это необходимо для SEO, а именно поисковой оптимизации статей, согласно правилам поисковых систем. Фразы одного кластера используются при написании одной статьи — в заголовках, метатегах и в самом тексте. Мы воспользовались умным кластеризатором на основе поисковой выдачи (кому интересно об этом можете почитать ЗДЕСЬ!, здесь или здесь). Вот что мы получили в итоге:
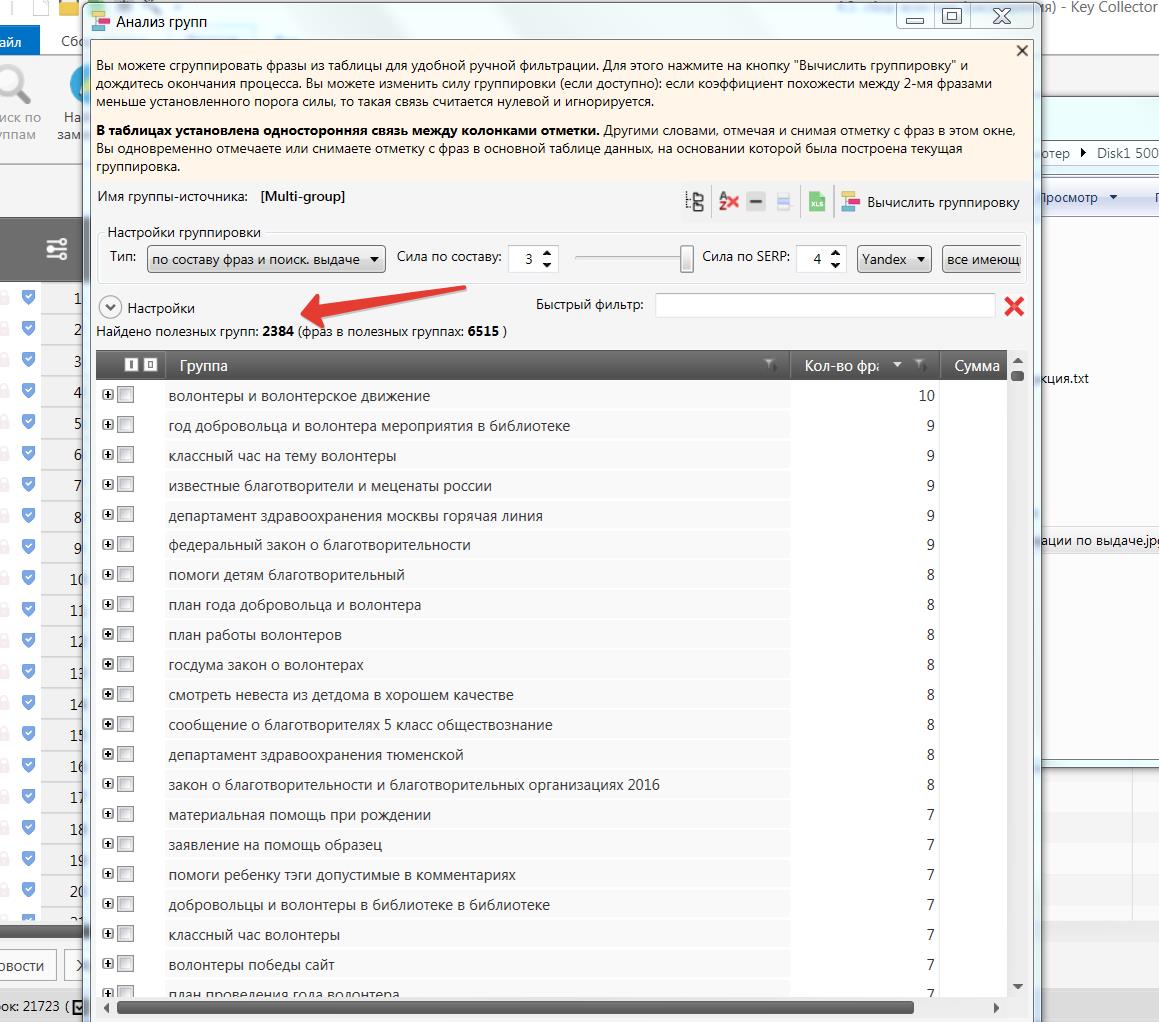
Скачать файл Excel со всеми кластерами: кластеризация.xlsx
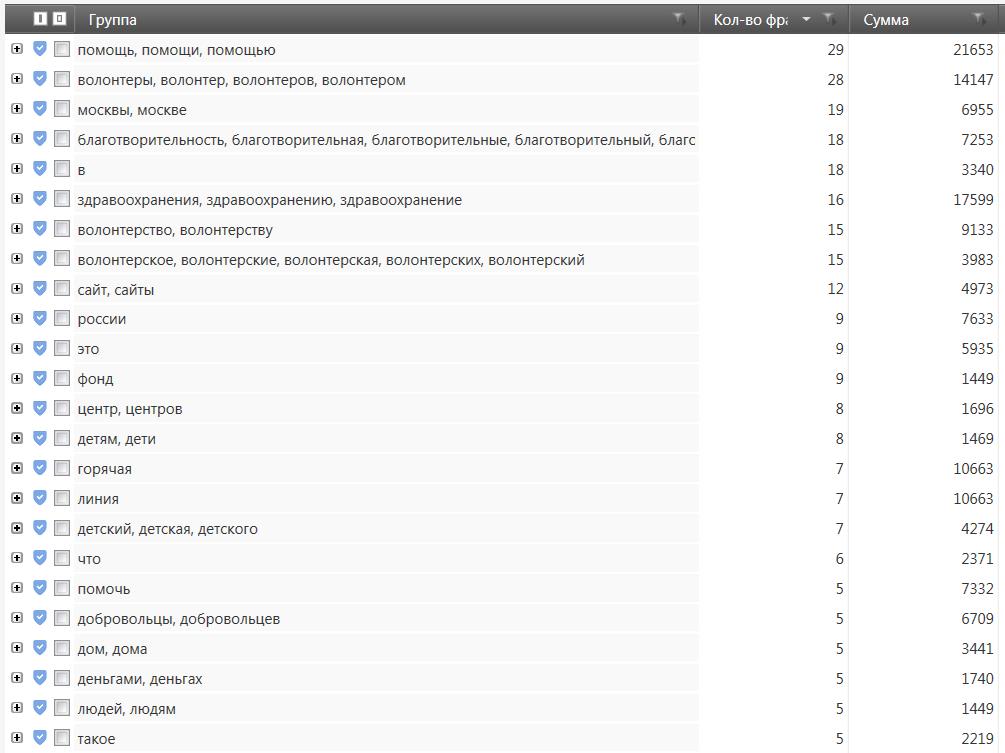
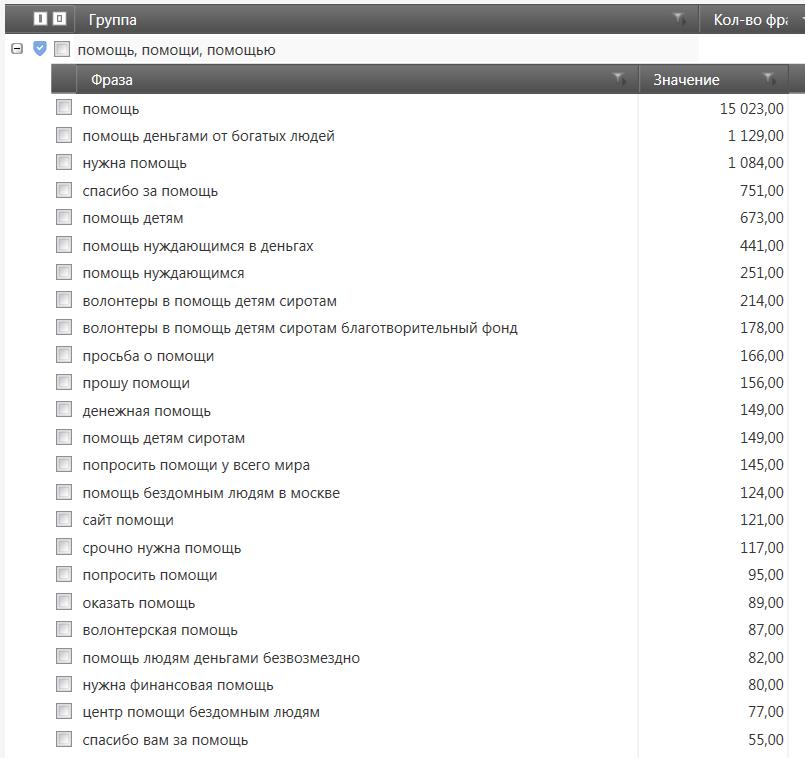
Как видите, у нас сформировалось огромное количество кластеров, аж более 2-х тысяч! Обратите внимание что для экспорта кластеров в таблицу Excel я взял только кластеры с количеством фраз равным 3 и более. Получилось более тысячи кластеров. Также вы можете заметить что здесь всё ещё присутствуют мусорные кластеры, я проделал лишь минимальную чистку. Естественно, для нашего сайта нет необходимости настолько подробно расширять СЯ, ведь написание такого количества статей под каждый кластер всё равно не представляется возможным. Однако в хорошо проработанном по охвату тематики и максимально собранном СЯ есть множество плюсов. Для дальнейшей работы с таким ядром мы можем использовать всевозможные фильтры чтобы отобрать наиболее «вкусные» запросы, которые лучше всего подходят нашему сайту и привлекут нам трафик.
Например, мы можем отсеять самые низкочастотные запросы (НЧ), и запросы с высоким уровнем конкуренции (ВК). Для оценки показателя конкуренции (KEI) для запросов я использую следующие данные от ПС Яндекс: количество документов в Топ-10 поисковой выдачи, количество главных страниц, количество внутренних страниц, и иногда стоимость кликов (но это обычно относится к коммерческим запросам). Подробно на подсчёте показателя KEI я сейчас не буду останавливаться, так как может быть множество разных вариантов формул (кому интересно можете посмотреть очень хорошую статью об этом ЗДЕСЬ! и здесь) При составлении этого СЯ я использовал простую формулу: (Кол-во главных страниц в выдаче ПС Яндекс по запросу)^3 + (Кол-во вхождений в заголовки страниц в ПС Яндекс)^3. А сейчас, на примере итогового СЯ, я лишь покажу вам каким образом я разметил список запросов по разным цветам для наглядности, в зависимости от значений частотностей и KEI.
Конечно, в результате автоматической кластеризации наши кластеры получились не идеально сгруппированными по смыслу. Теперь предстоит кропотливая доработка СЯ. Во первых: мы должны распределить эти кластеры по нашей основной структуре, с учетом иерархии разделов и подразделов. Во-вторых: ручной просмотр каждого кластера и вникание в смысл, корректировка кластеров таким образом, чтобы все запросы внутри них соответствовали единому интенту (поисковой потребности). При этом попутно продолжаем обнаруживать мусорные запросы, удалять их и пополнять список стоп-слов.
Итак! Вот какое семантическое ядро я получил в результате ручной группировки кластеров.
Файл готового СЯ: СЯ.xlsx
Всего в нём около 3000 кластеризованных и сгруппированных запросов (+ более 10000 в списке резервных запросов для дальнейшей чистки и обработки). Оно представляет из себя иерархическую структуру (разделов, подразделов и т д..) распределенную по листам в Excel, на первом из которых содержание всех разделов. Такого СЯ вполне хватит для начала развития сайта, а самое главное теперь сосредоточиться на контенте — обеспечить наполнение сайта качественными уникальными информационными статьями и другими видами материалов (тесты, опросы, каталоги, таблицы, галереи, медиафайлы и т д..)
А в перспективе для постепенного расширения СЯ у меня остались подготовлены в обшей сложности несколько десятков тысяч тематических фраз, с которыми планирую постепенно работать. Это около 20000 несгруппированных и некластеризованных запросов, несколько тысяч готовых очищенных кластеров, готовых для ручной группировки. Всё это я буду использовать в качестве резервного списка для расширения ядра.
Строки колорированы в разные цвета в зависимости от показателя KEI:
- 0 – конкуренция отсутствует, это самые свободные и незанятые ключи, нужно брать в первую очередь. (без цвета)
- От 1 до 9 – простые запросы, выйти в ТОП относительно легко. (зелёный)
- От 10 до 100 – средний уровень конкуренции, за место в ТОП нужно будет побороться. (жёлтый)
- От 101 и выше – сложные запросы, конкурентная тематика, нужно хорошо подумать, прежде чем браться за них. (красный)
ПС: Напомню что это СЯ всё ещё на стадии доработки и расширения. Также кому интересно самому «пощупать» реальность этих цифр, то частотности по любым фразам вы можете самостоятельно сверить по Вордстату.
Благодарю всех кто сумел дочитать до конца ?. Удачи!
 (1 оценок, среднее: 5,00 из 5)
(1 оценок, среднее: 5,00 из 5)





